Defective main memory can disrupt business operations with performance degradation or hardware crashes, leading to costly downtime. Dynamic random access memory (DRAM) modules typically have built-in mechanisms that address memory errors. This post answers the most common questions on computer memory errors to help you ensure high availability and maximum reliability of DRAM installed in your mission-critical systems.
What are the types of memory errors?
Memory errors fall into two broad categories:
Soft Memory Errors are those that randomly corrupt memory bits and alter stored data but do not cause physical damage to the memory module. Soft memory errors damage the data being processed rather than the system hardware, but in mission-critical applications such as medical equipment, industrial controllers, autonomous cars, security/surveillance systems and data centers, uncorrected soft errors may lead to catastrophic outcomes.
There are two types of soft memory errors:
- Chip-Level Soft Errors are usually due to the radioactive decay of elements in the memory chip packaging. When these alpha particles hit the chip, they cause the cell to change its state to a different value, create an imbalance in the electrical properties of the chip, and cause stored data to be corrupted. Due to advancements in memory design and technology, these types of errors are now rare, as it takes about 10 years for the chip materials' radioactive elements to decay.
- System-Level Soft Errors usually occur when the data being processed is hit with a glitch or noise while data is on the data bus. Noise is interference or static that destroys signal integrity and can come from electromagnetic interference (EMI) radio waves, electrical wiring, lightning, bad connections, and other sources. The noise could be misinterpreted by the system to be a data bit and uses or executes the bad data bit or program code, resulting in an error.
Hard memory errors are errors that keep recurring as a result of hardware or physical defects on the memory module. Hard memory errors are commonly caused by operating a system beyond the memory's speed capacity and subjecting the system to charges of static electricity. Other causes include environmental factors such as temperature, shock/vibration, electrical/voltage stress or physical stress. Mishandling, aging, or manufacturing defects can also affect the reliability of hardware components. Hard errors are usually permanent and require module replacement.
How can you tell if the memory error is soft or hard?
Soft memory errors can typically be rectified by rebooting the system. If the system is rebooted and the errors keep recurring, they are most likely caused by hard errors and the solution is to replace the memory chip or module entirely.
How costly are memory errors?
At best, memory errors can degrade performance. At worst, they can cause system crashes. Aside from hardware repair and replacement costs, memory failures can cause major end-user service disruptions, damage important data and consequently affect general operations.
What external factors affect memory performance and reliability?
Extreme temperatures are generally considered to impact the physical makeup of memory because they cause physical changes to the materials or components, so companies make considerable investments on thermal and cooling solutions. Increased utilization and DIMM age can also affect memory performance and reliability and increase the severity of memory errors.
What error correction mechanisms are available and how do such mechanisms work?
In mission-critical applications where data corruption and system failure must be avoided, dual in-line memory modules (DIMMs) with error correcting code (ECC) are used. ECC DIMMs can do either single-bit error correction (SEC) or SEC and double-bit error detection (SECDED). SEC alone cannot detect double-bit errors so it will report the memory as error free if there are two error bits. SECDED, on the other hand, can detect all single- and double-bit errors but will correct only single-bit errors. It is unable to detect triple-bit errors or correct double-bit errors.More advanced error detection and correction can be handled by more complex codes such as ChipKill™ or Advanced ECC memory, which is capable of detecting and correcting multi-bit errors that standard ECC cannot correct. Developed specifically for the NASA pathfinder mission to Mars, ChipKill works by creating a duplicate set of data in the form of a checksum in another part of the memory subsystem. When memory failure occurs, data recovery is done by recalculating the data from the checksum information, allowing the DIMM to withstand even the failure of an entire DRAM chip and resulting in better system availability. Studies have shown that ChipKill reduces uncorrectable error rates by up to 4X compared to SECDED.
What are correctable and non-correctable errors?
Correctable errors are generally single-bit errors that the system or the built-in ECC mechanism can correct. These errors do not cause system downtime of data corruption. Uncorrectable errors are generally multi-bit errors that could cause the system to crash or shut down immediately.
Physically, how does an ECC DIMM differ from a non-ECC DIMM?
If the number of chips on the module is divisible by three, the module is an ECC DIMM. Standard RAM has eight memory chips that store data, providing it to the CPU on demand. An ECC memory module has an additional memory chip to detect and correct errors for the eight chips. The table below shows illustrations of ECC and non-ECC DIMMs from ATP.
|
DIMM Type |
ECC |
Non-ECC |
|
DDR4 |
Registered |
|
|
DDR3 |
Registered |
|
|
Unbuffered |
Unbuffered |
|
|
DDR2 |
Registered
|
|
|
Unbuffered |
Unbuffered |
|
|
DDR |
Registered |
|
|
Unbuffered |
Unbuffered |
|
















Table 1. ATP DDR/DDR2/DDR3/DDR4 ECC and non-ECC DIMMs.
ATP DRAM Differentiators
ATP DRAM products are used in applications where the highest degree of reliability is required. Memory errors can have a major impact on operations, so ATP painstakingly ensures that all its DRAM products meet the toughest standards.
- Functional Testing: Automatic Testing Equipment (ATE)
Major integrated chips (ICs) used in ATP DRAM products are sourced from Tier 1 manufacturers and undergo meticulous testing to ensure excellent reliability and longevity. All DRAM modules undergo stringent functional testing using the Automatic Testing Equipment (ATE) to detect structural and component defects and to screen out marginal timings and signal integrity (SI).

Figure 1. Functional testing using ATP Automatic Testing Equipment (ATE).
-
System Testing: Test During Burn-In (TDBI)
At mass production (MP) level, all the modules are subjected to Test During Burn-In (TDBI), which combines temperature, load, speed and time to stress-test the memory module and to screen out weak ICs. ATP's TDBI aims to effectively screen out defective DRAM chips that will potentially fail during the early life failure (ELF) period. By ensuring that only robust DRAM chips are on the module, TDBI significantly lowers failure rates and extends the product service life.
Since even just 0.01% error on a 99.99% effective device can increase the failure rates at module level and lead to failure in actual usage, TDBI detects and screens out the 0.01% error to ensure the DRAM modules' reliability.
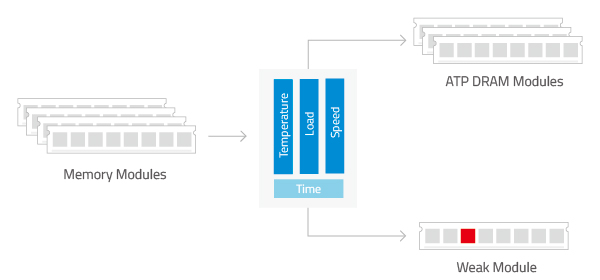
Figure 2. ATP Test During Burn-In (TDBI) for 100% of DRAM modules at mass production (MP) level screens out weak ICs.
-
ATP Mini Chamber
During TDBI, the specially designed ATP Mini Chamber isolates the temperature cycling to the targeted area so only the modules are subjected to burn-in. This makes it easy to find the root cause of failure and keeps the motherboard in stable operation.

Figure 3. ATP Mini Chamber subjects only the DRAM modules to temperature cycling.
ATP's industrial DRAM products are available in legacy SDRAM and a complete range of DDR1, DDR2, DDR3 and DDR4 modules including the latest DDR4-2666 in different densities and form factors. For more information, visit the ATP website or visit an ATP Distributor/Representative in your area.